

Have you heard of Apache Spark? It is a leading framework for processing big data. Let me introduce it to you!
I first heard about Spark just over 2 years ago when I started working on the project related to consented tracking of consumer data, building audiences, creating target ad campaigns and aggregating detailed analytics. It’s a DMP platform with unique long-lasting cross-device technology. At the same time, I got acquainted with the Scala programming language in which Spark was written. All this fascinated me so much that I devoted all the subsequent time to studying these and several related technologies. Today I’ll focus your attention on Spark.
Nowadays Spark is used in lots of leading companies such as Amazon, eBay, Nasa, etc. Many organizations operate Spark in clusters, involving thousands of nodes. According to the Spark FAQ, the largest of these clusters have more than 8,000 nodes.
What is Apache Spark?
Apache Spark is a unified analytics engine for large-scale data processing. The project is being developed by the free community, currently, it is the most active of the Apache projects. Comparing to Hadoop MapReduce, another data processing platform, Spark accelerates the programs operating in memory by more than 100 times, and on drive – by more than 10 times. Furthermore, the code is written faster because here in Spark we have more high-level operators at our disposal. Natively Spark supports Scala, Python, and Java. It is well integrated with the Hadoop ecosystem and data sources.
Spark main components
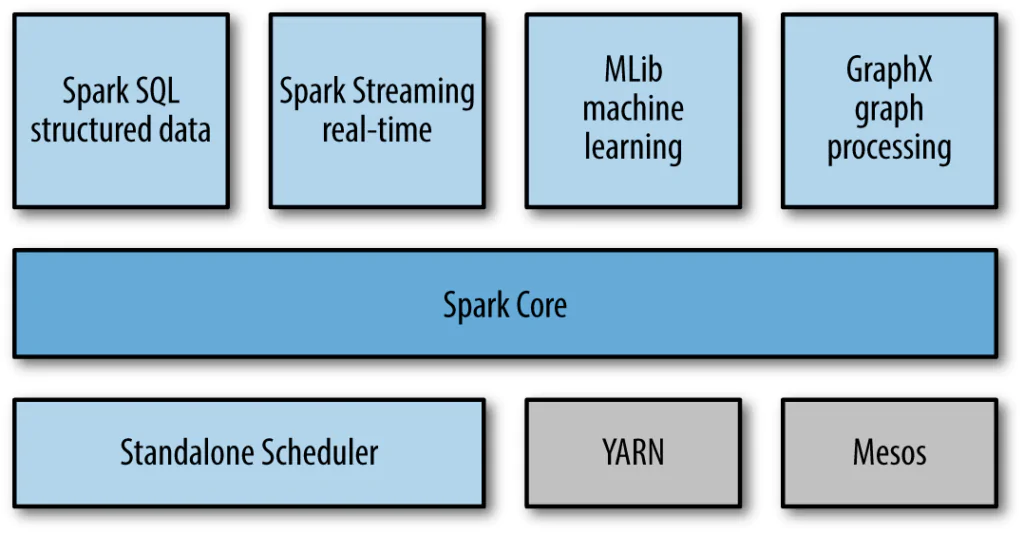
Apache Spark components
SQL & DataFrames is a Spark component that supports data querying using either SQL or DataFrame API. Both help to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC in the usual way. There is even a possibility to join data across the mentioned sources.
Spark Streaming supports real-time streaming processing. Such data can be log files of the working web server (for example, processed by Apache Flume or placed on HDFS / S3), information from social networks (for example, Twitter), as well as various message queues such as Kafka.
MLlib is a machine learning library that provides various algorithms designed for horizontal scaling on a cluster for classification, regression, clustering, co-filtering, etc.
GraphX is a library for manipulating graphs and performing parallel operations with them. The library provides a universal tool for ETL, research analysis and graph-based iterative computing.
Spark Core is a basic engine for a large-scale parallel and distributed data processing. The core is responsible for:
- memory management and recovery after failures
- planning, distribution, and tracking of tasks in a cluster
- interaction with storage systems
Cluster Managers are used for the management of the Spark work in a cluster of servers.
What can you do with Spark?

Apache Spark Application
- Spark helps to create reports quickly, perform aggregations of a large amount of both static data and streams.
- It solves the problem of machine learning and distributed data integration. It is easy enough to do. By the way, data scientists may use Spark features through R- and Python-connectors.
- It copes with the problem of “everything with everything” integration. There is a huge amount of Spark connectors. Spark can be used as a quick filter to reduce the dimension of the input data. For example, transmit, filtering and aggregating a flow from Kafka, adding it to MySQL, etc.
The Scope of Apache Spark application
Potentially, the coverage of Spark is very extensive. Here is an indicative (but not exhaustive) selection of some practical situations where a high-speed, diverse and volumetric processing of big data is required for which Spark is so well suited:
Online Marketing
- ETL
- Creation of analytical reports
- Profiles classification
- Behavior analysis
- Profiles segmentation
- Targeted advertising
- Semantic search systems
Media & Entertainment
- Recommendation systems
- Schedule optimization
- Expansion and retention of the audience
- Targeted advertising
- Content monetization
Government
- Intelligence and cybersecurity
- Felony prediction and prevention
- Weather forecasting
- Tax implementation
- Traffic streamlining
Healthcare
- Pharmaceutical drug assessment
- Scientific research
- Data processing of:
- patient records
- CRM
- weather forecasting
- fitness trackers
- demographic data
- research data
- data from devices and sensors
Finances
- Employee surveillance
- Predictive modeling
- Financial markets forecasting
- Auto insurance
- Consumer credit operations
- Loans
Manufacturing
- Behavior analysis
- Creation of analytical reports
- Data processing from devices and sensors
- Targeted advertising
- CRM
- Employee monitoring
Logistics & Mobility
- ETL of sensors data
- Weather forecasting
- Predictive analytics
- Creation of analytical reports
Agricultural
- Weather forecasting
- ETL from:
- Soil sensors
- Drones
- Monitoring gadgets
What challenges do you usually face while working with Spark?

Possible challenges
In fact, challenges are typical for any big data framework.
Things that work on a small dataset (test methods and some JVM settings) often work differently on big data in production.
Another possible challenge for a Java or Python developer is that you need to learn Scala. Most of the code base and function signatures require reading the Scala code with a dictionary.
And last but not at least, even a small home project is expensive if you test it in the cluster.
Where is Spark heading?
Spark is a very dynamic platform. That was relevant a year or two ago, now it has been replaced by more optimal components. If you buy a book about Spark, you risk getting outdated knowledge. Because while this book was being written, many changes in Spark happened. For example, there are three APIs for working with data now. They all appeared not immediately, but consistently. Each of these APIs was better than the previous ones. As a result, you often have to work with several of these interfaces in parallel that is a certain disadvantage. I think in the future there will be a single API for all components. Spark is also following the path of strong integration with Machine Learning and Deep Learning.
Conclusion
So, Spark helps to simplify non-trivial tasks related to the high computational load, the processing of big data (both in real time and archived), both structured and unstructured. Spark provides seamless integration of complex features — for example, machine learning and algorithms for working with graphs. Spark carries the processing of Big Data to the masses. Try it in your project – and you will not regret!
Market report

Subscribe


Thank you!
Get ready! You will receive handpicked content right to your inbox.